时隔两年再次发一篇Blog,记录一下这个Flink测试过程中遇到各种问题,一个简单的Job竟然耗费了6个小时才完成。Job要求如下:
自定义 TableSource,从标准输入中按行读取数据,每行按逗号分隔字段。表的 schema 为 (id int, name string, age int)
自定义 TableSink,将 Table 数据写到标准输出
通过 SQL 实现 select name, max(age) from student group by name
实现代码如下:
/**
* Flink版本 1.9.1
*/
public class StreamTableSQLDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment streamTableEnv = StreamTableEnvironment.create(streamEnv);
//使用自定义的dataSource
String[] fieldNames = {"id", "name", "age"};
DataType[] fieldTypes = {DataTypes.INT(), DataTypes.STRING(), DataTypes.INT()};
TableSource studentSource = new SystemInDataSource(fieldNames, fieldTypes);
//注册为table
streamTableEnv.registerTableSource("student", studentSource);
//使用自定义的sink,打印数据到标准输出
TableSink studentSink = new PrintTableSink(fieldNames, fieldTypes);
streamTableEnv.registerTableSink("result_student", studentSink );
streamTableEnv.sqlUpdate("insert into result_student select id, name, age from student");
//执行SQL
Table tableAfterGroup = streamTableEnv.sqlQuery("select name, max(age) from student group by name");
DataStream<Tuple2<Boolean, Row>> result = streamTableEnv.toRetractStream(tableAfterGroup, Row.class);
//打印输出
result.print();
streamEnv.execute("Stream Table SQL Demo");
}
/**
* 自定义标准输入Source
*/
public static class SystemInDataSource implements StreamTableSource<Row>, DefinedFieldMapping {
private TableSchema tableSchema;
private SystemInDataSource(String[] fieldNames, DataType[] fieldTypes){
this.tableSchema = TableSchema.builder().fields(fieldNames,fieldTypes).build();
}
@Override
public DataType getProducedDataType() {
return DataTypes.ROW(DataTypes.FIELD("f0", DataTypes.INT()),
DataTypes.FIELD("f1", DataTypes.STRING()),
DataTypes.FIELD("f2", DataTypes.INT()));
}
@Override
public DataStream<Row> getDataStream(StreamExecutionEnvironment streamExecutionEnvironment) {
return streamExecutionEnvironment.addSource(new SystemInSourceFunction());
}
@Override
public TableSchema getTableSchema() {
return tableSchema;
}
/**
* 定义映射关系
* @return
*/
@Nullable
@Override
public Map<String, String> getFieldMapping() {
Map<String, String> mapping = new HashMap<>();
mapping.put("id", "f0");
mapping.put("name", "f1");
mapping.put("age", "f2");
return mapping;
}
}
/**
* 自定义的标准输入SourceFunction
*/
public static class SystemInSourceFunction implements SourceFunction<Row>, ResultTypeQueryable<Row> {
@Override
public TypeInformation<Row> getProducedType() {
return Types.ROW(Types.INT, Types.STRING, Types.INT);
}
@Override
public void run(SourceContext<Row> sourceContext) throws Exception {
while(true){
System.out.print("请输入: ");
Scanner scanner = new Scanner(System.in);
String line = scanner.next();
String [] str = line.split(",");
if(str.length == 3){
Row element = Row.of(Integer.valueOf(str[0]), str[1], Integer.valueOf(str[2]));
sourceContext.collect(element);
} else {
System.err.println("输入格式错误.");
}
}
}
@Override
public void cancel() {
}
}
/**
* 自定义标准输出Sink
*/
public static class PrintTableSink implements AppendStreamTableSink<Row> {
private TableSchema tableSchema;
private PrintTableSink(String[] fieldNames, DataType[] fieldTypes){
this.tableSchema = TableSchema.builder().fields(fieldNames,fieldTypes).build();
}
@Override
public TableSchema getTableSchema() {
return tableSchema;
}
@Override
public DataType getConsumedDataType() {
return tableSchema.toRowDataType();
}
@Override
public DataStreamSink<?> consumeDataStream(DataStream<Row> dataStream) {
return dataStream.addSink(new SinkFunction());
}
@Override
public TableSink configure(String[] strings, TypeInformation<?>[] typeInformations) {
return this;
}
@Override
public void emitDataStream(DataStream dataStream) {
}
private static class SinkFunction extends RichSinkFunction<Row> {
public SinkFunction() {
}
@Override
public void invoke(Row value, Context context) throws Exception {
System.out.println("收到了新的输入: " + value);
}
}
}
}
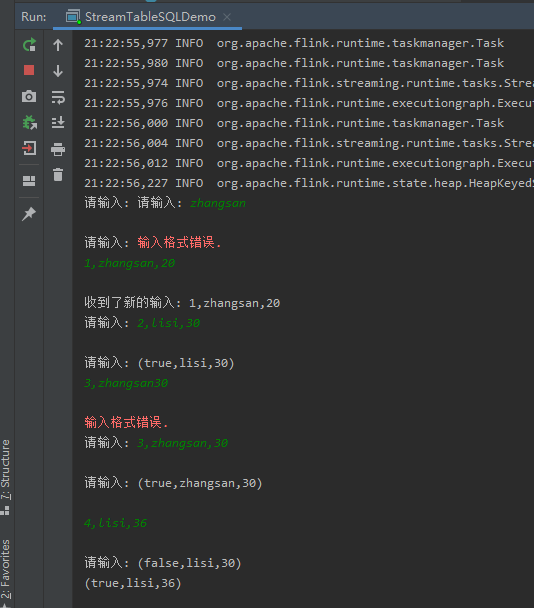
运行测试,依次输入以下内容:
zhangsan
1,zhangsan,20
2,lisi,30
3,zhangsan,25
4,lisi,36
理论上首先会输出格式错误,然后依次输出结构,并且采用Retract打印当前max(age)结果。
截图如下:
Flink自定义TableSource/TableSink Job
自学flink中