背景:
前期项目存储采用hdfs作为分布式文件系统,搭建hbase作为数据的存储平台,项目在开发以及上线过程中一直未配置压缩选项,随着数据的累积,很短时间,发现仅仅不到2亿数据已经占用400GB的存储空间,由于平台搭建预分配硬盘并不是非常充裕,所以需要开始着手配置hbase表的压缩。
测试环境:
- 笔记本:i7-3630QM 2.4GB + 12GB + 240GB Intel530 SSD
- 三台Vmware搭建的Linux虚拟机:RHEL 6.5 64位系统
- hadoop版本:hadoop-2.6.0-cdh5.4.4
- hbase版本:hbase-1.0.0-cdh5.4.4
安装步骤:
1.检查其他组件是否存在以及版本是否对应,主要包括以下:
1.1 protoc
下载地址:https://github.com/google/protobuf
需下载对应版本的进行编译,编译步骤参照README提示安装,一般步骤是./autogen.sh; configure; make ; make install 这四步,但是可能依赖于gtest或者gmock这些库,由于默认下载需要翻墙,所以可以采取配置代理,或者翻墙下载好源码包之后,按照autogen.sh脚本要求放到指定位置即可。
我这里采用的protoc版本是2.5.0,安装完成后可执行protoc -version检查版本是否正确。
1.2 cmake
下载地址:http://www.cmake.org/cmake/resources/software.html
下载完成后,配置cmake的bin到环境变量PATH中。
这里采用的版本是3.4.0,可以执行cmake -version检查版本
1.3.snappy
下载地址:https://github.com/google/snappy
编译方式同protoc一致,依次执行 ./autogen.sh; ./configure; make ; make install 默认安装到/usr/local/lib目录下。安装完成后检查该目录即可。
1.4.maven
maven是一个项目依赖构建的工具,类似于Makefile,Ant这样的工具,但是又不一样,具体可以查看相关资料,推荐《Maven实战》这本书。
下载地址:http://maven.apache.org/download.html
下载解压后,配置bin到环境变量PATH中
2.编译hadoop
hadoop源码位置位于 $HADOOP_HOME/src目录
切换到该目录执行如下命令:
mvn clean package -DskipTests -Pdist,native -Dtar -Dsnappy.lib=/usr/local/lib -Dbundle.snappy
其中-Dsnappy.lib指定是snappy编译后的位置。
如果一切OK之后,编译成功。我的虚拟机是2核心1GB内存,编译大概花了30分钟。
特别注意的是,编译hadoop需要大概5GB以上的剩余空间,由于我的测试环境硬盘只有不到2GB,导致编译失败。
编译成功后,编译后的hadoop在 $HADOOP_HOME/src/hadoop-dist/target/hadoop-2.6.0-cdh5.4.4.tar.gz,可以在此基础上,拷贝到hadoop安装位置,解压,修改配置etc目录,由于我之前已经配置过etc目录,我把编译之前的etc目录直接拷贝过来覆盖此etc,然后修改配置文件如下:
2.1.修改 $HADOOP_HOME/etc/hadoop/core-site.xml:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
</property>
2.2.修改 $HADOOP_HOME/etc/hadoop/mapred-site.xml 中有关压缩属性
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
2.3.copy动态库和修改配置到集群中所有的节点中。
2.4.重启hadoop集群
stop-yarn.sh
stop-dfs.sh
start-dfs.sh
start-yarn.sh
检查hadoop集群状态,比如通过web工具50070端口查看等。
2.5.执行hadoop checknative查看snappy是否已编译成功,如下:
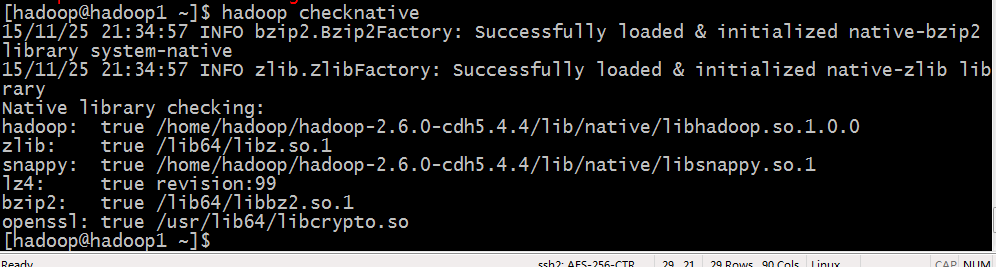
2.6 修改hbase配置文件hbase-site.xml,增加如下配置,这样hbase在启动时会主动加载snappy codec,如果加载不成功,会报错util.CompressionTest: Can't instantiate codec: snappy
<property><name>hbase.regionserver.codecs</name><value>snappy</value></property>
2.7 在$HBASE_HOME/lib目录下,新建native文件夹,然后在native文件夹下创建Linux-amd64-64文件夹,在native/Linux-amd64-64下拷贝过来$HADOOP_HOME/lib/native下的所有文件,这也是最重要的一步。(2015.12.05补充)
注意分发修改后的配置文件和lib目录,然后重启hbase集群,如果hbase集群启动成功,则配置成功。
mkdir -p $HBASE_HOME/lib/native/Linux-amd64-64
cp $HODOOP_HOME/lib/native/* HBASE_HOME/lib/native/Linux-amd64-64/
#分发目录到各子节点
stop-hbase.sh
start-hbase.sh
#jps查看各节点启动情况,如果启动失败,检查日志。
3.修改HBase表,配置snappy压缩选项
3.1 打开hbase shell
hbase shell
3.2 disable表
disable 'test'
3.3 修改压缩选项,这里f是列族,需要对每个列族进行修改
alter 'test', NAME =>'f', COMPRESSION => 'snappy'
3.4 重新enable表
enable 'test'
3.5 major_compact表,该动作耗时较长
major_compact 'test'
3.6 describle表
可看到COMPRESSION => 'snappy'
实测结果:
我在虚拟机中只有4万条数据,压缩前大小是319MB,压缩后大小是280MB,压缩效果并没有很多资料上说的那么好,具体原因未知,可能是我直接统计/hbase目录不太准确的原因,明天我在实际生产环境部署后,再测试压缩效果。
2015.12.05更新:
由于原有配置完成后,hbase启动时加载snappy codec失败,导致配置hbase表之后无法压缩。最终修改配置之后,压缩效果如下图:
压缩前:data目录为319.0MB
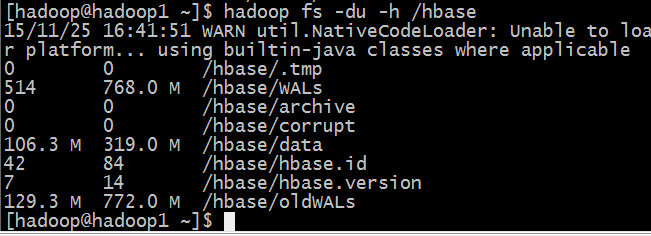
压缩后:data目录为59.2MB
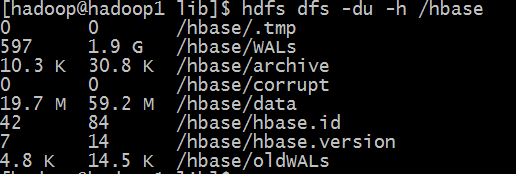
压缩比为59.2/319.0 ≈ 18.56%
后记:
很多资料中,需要编译hadoop snappy源码,然后拷贝jar包和native到hadoop指定目录中,这实际是hadoop1.0采取的措施,在hadoop2.x源码已经集成了Snappy压缩jar包了,所以编译安装
hadoop-snappy 根本是多余的,只要安装snappy本地库和重新编译hadoop native 库就行。
参考资料:
- HBase修改压缩格式及Snappy压缩实测分享:http://www.cnblogs.com/shitouer/p/hbase-table-alter-compression-type-and-snappy-compression-compare.html
- Hadoop2.2.0源码编译 : http://www.micmiu.com/bigdata/hadoop/hadoop-build-source-2-2-0/
- Hadoop安装配置snappy压缩:http://www.micmiu.com/bigdata/hadoop/hadoop-snappy-install-config/
- 关于几种压缩算法以及hadoop和hbase中的压缩配置说明:http://blog.csdn.net/yangbutao/article/details/8474731
- HBase使用SNAPPY压缩遇到compression test fail问题解决 http://www.07net01.com/linux/HBaseshiyongSNAPPYyasuoyudaocompression_test_failwentijiejue_587371_1379500070.html
你好
我执行./hadoop checknative -a之后
那些压缩算法都对了,但是
openssl: false build does not support openssl.
请问,这个是为什么?会影响使用吗?
我也遇到过这个问题,只要你的环境没用ssl应该不影响使用。
你好,我看$HADOOP_HOME/lib/native目录中的snappy是链接文件,我在A机器编译,现在想应用到B机器的HBase中,是不是只需要在B机器安装snappy即可呢?
如果两个机器的配置环境一样,直接拷贝.so文件过去就行