在使用Solr过程中,有时候为了对数据进行分别管理,我们要创建多个collection以及多个shard来管理索引数据。但是问题随之而来,如何跨collection查询数据?在发现Collection API中的CREATEALIAS之前,我们想过采用程序自己去实现分布式查询路由。最近看Solr官方文档过程中,发现采用CREATEALIAS可以对多个collection创建一个alias。于是尝试能否通过alias实现跨collection查询。
测试环境
- Solr版本:CDH5.4.4-solr4.10.3
- 在SolrCloud模式下启动6个Solr实例
- 采用独立的zookeeper集群
测试过程
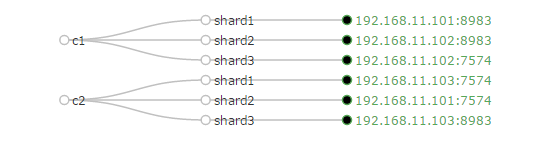
1. 创建两个采用相同config,相同schema的Collection,分别命名为c1,c2
采用如下API接口:
http://192.168.11.101:8983/solr/admin/collections?action=CREATE&name=c1&numShards=3&replicationFactor=1&maxShardsPerNode=1&collection.configName=myconf
http://192.168.11.101:8983/solr/admin/collections?action=CREATE&name=c2&numShards=3&replicationFactor=1&maxShardsPerNode=1&collection.configName=myconf
==其中myconf已经通过上传到zookeeper中/solr/configs目录下。==
创建成功后在Web中可以看到如下结果:
2. 采用SolrJ向两个Collection插入数据
向c1中插入id从0-19的数据
cloudSolrServer.setDefaultCollection("c1");
...
List<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
for(int i=0; i<20; i++){
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", i);
doc.addField("title", "abc"+i);
docs.add(doc);
}
try {
cloudSolrServer.add(docs);
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
向c2中插入id从20-39的数据,代码同上。
3. 分别查询c1和c2数据,可以看到各自的索引数据
截图:略
4. 为c1和c2创建别名cc
http://192.168.11.101:8983/solr/admin/collections?action=CREATEALIAS&name=cc&collections=c1,c2
5. 使用cc作为defaultCollection使用cloudSolrServer去查询
cloudSolrServer.setDefaultCollection("cc");
...
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
query.setStart(0);
query.setRows(100);
try {
QueryResponse response = cloudSolrServer.query(query);
SolrDocumentList results = response.getResults();
System.out.println("Total : " + results.size());
for(SolrDocument doc : results){
System.out.println(doc.getFieldValue("title"));
}
} catch (SolrServerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
查询结果可以看到包含了c1(20条)和c2(条)中所有的数据,共计40条数据。结果如下:

总结
以上就是在SolrCloud模式下通过SolrJ的跨collection查询。在使用HTTP API时,我们可以直接指定collection list来进行查询。如下:
http://localhost:8983/solr/collection1/select?q=test&collection=collection1,collection2,collection3
在Solr单实例模式下,通常是通过指定shards参数来指定要查询solr实例,如下:
http://localhost:8983/solr/collection1/select?q=test&shards=10.0.0.1:8983/solr/collection1,10.0.0.2:8983/solr/collection1,10.0.0.3:8983/solr/collection1
其中10.0.0.2:8983/solr/collection1,10.0.0.3:8983/solr/collection1为独立的solr实例。其原理和SolrCloud的跨shards查询是一样的。
参考
https://wiki.apache.org/solr/SolrCloud
https://wiki.apache.org/solr/DistributedSearch
多谢作者的分享,很受启发。最近正在苦恼公司有好几个collection要怎么整合到一起。准备去试下alias。不过看来在这之前,我需要统一下几个collection的schame,再将id处理一下。 话说,如果c1和c2中有重复的id,不知道会怎么样?报错?
应该都会返回,因为这个id应该在collection范围内的概念。而通过alias查询,应该是将一个查询请求分布式的请求到对应的collections中,然后将获取的结果合并返回。具体我没有测试过,我觉得应该是这样。
我去试了下。发现不用处理id,连schame都不用统一。这真是太方便了