在之前的文章里,我使用了rabbitmq作为storm-topololy中spout的数据来源,使用storm-rabbitmq作为spout直接使用。通常我们的业务逻辑如下:
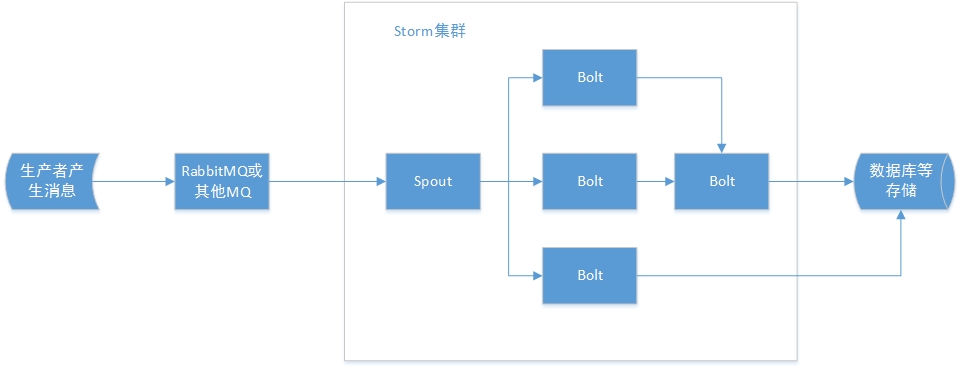
在bolt对tuple进行处理之后,通常要将数据缓存到redis,memcached等内存数据库中,对于数据量小的,可以缓存到内存中,但是对于大量持久化的数据,更多时候需要存储到分布式存储系统中,这里我选择HBase用于存储结果。
参照官方文档,storm提供storm-hbase项目用于集成storm-hbase
github地址:https://github.com/ptgoetz/storm-hbase
clone之后需要修改maven依赖的软件版本,其中hbase采用是0.98版本,但是我的测试环境是1.0.0版本,两个版本的API差别还是有一些的,如HTable变成了Table等。为了测试,我fork该项目修改hbase为1.0.0用于项目开发。
github地址:https://github.com/mengzhiyi/storm-hbase-1.0.x
测试环境: Storm 0.9.6 + HBase 1.0.0
Storm-HBase使用步骤:
1.首先我们在Hbase创建一个测试表,表名是stormTest,包括c1,c2两个列族
create 'stormTest', c1, c2
2.在代码中,我们需要实现org.apache.storm.hbase.bolt.mapper.HBaseMapper接口,用于表示Tuple与HBase中“一行数据”的映射关系。本文示例采用上文中storm-rabbitmq的tuple的字符串作为输出,rowkey使用id,c1列族下包含str列,c2列族下包含num列。代码如下:
[java]
/**
* 自定义tuple与hbase数据行的映射
* @author adam
*
*/
public class MyHBaseMapper implements HBaseMapper {
public ColumnList columns(Tuple tuple) {
ColumnList cols = new ColumnList();
//参数依次是列族名,列名,值
cols.addColumn("c1".getBytes(), "str".getBytes(), tuple.getStringByField("str").getBytes());
cols.addColumn("c2".getBytes(), "num".getBytes(), tuple.getStringByField("num").getBytes());
return cols;
}
public byte[] rowKey(Tuple tuple) {
//根据tuple指定id作为rowkey
return tuple.getStringByField("id").getBytes();
}
}
[/java]
3.在Topology定义Bolt,如下:
[java]
HBaseMapper mapper = new MyHBaseMapper();
HBaseBolt hbaseBolt = new HBaseBolt("stormTest", mapper).withConfigKey("hbase.conf");
[/java]
4.另外,需要指定HBase根目录用于获取hbase-site.xml文件,如下:
[java]
Config conf = new Config();
conf.setDebug(true);
Map<String, Object> hbConf = new HashMap<String, Object>();
hbConf.put("hbase.rootdir", "HBASE根目录");
conf.put("hbase.conf", hbConf);
[/java]
其中HBase根目录可以通过properties文件指定或者通过启动项args列表来指定。
启动运行后,存储的数据如下所示:
